

No artigo de hoje vamos entender como identificar valores repetidos e ou duplicados numa tabela. Não são raras as situações em que precisamos ou queremos identifica-los e, por exemplo, excluir estes valores.
Podemos trabalhar com estes valores repetidos ou duplicados de duas maneiras. A primeira é aplicando a formatação condicional para identificar quais são estes valores. A segunda é realmente removendo estes valores, com a opção de “Remover Duplicatas”.
Vamos supor que temos uma lista de valores como a mostrada abaixo:
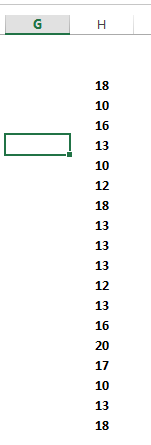

São 18 valores e, dentre eles, vários repetidos. Primeiramente, utilizando a formatação condicional vamos identifica-los. Selecionamos todos os valores e vamos ao menu da página inicial, selecionamos a opção “Formatação Condicional”.
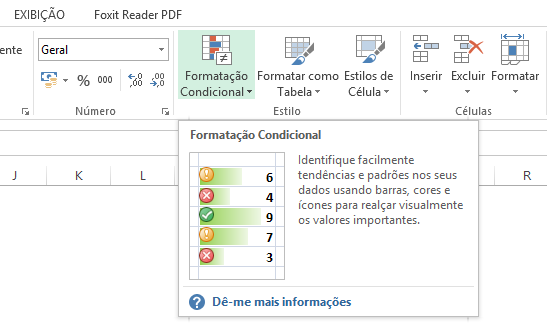

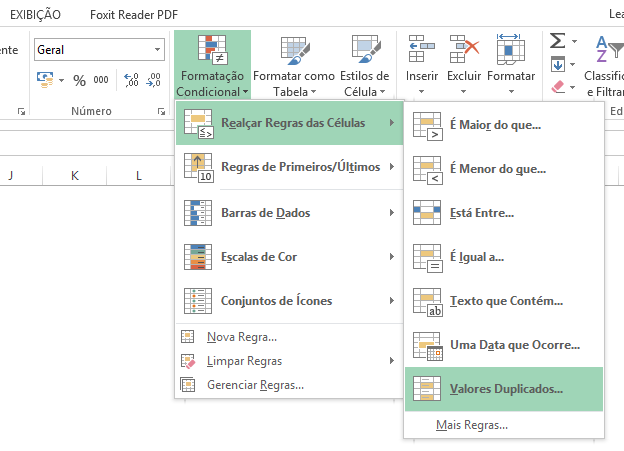
Em seguidas, vamos na opção “Realçar Regras das Células” e depois em “Valores Duplicados”.

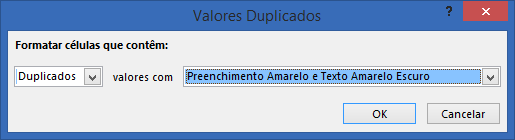
Na janela que se abriu, escolha a opção como mostra a imagem abaixo.

Pronto. Sua tabela terá todos os dados duplicados realçados como abaixo.


Repare que os valores 20 e 17 não possuem nenhuma repetição, por isso não foram formatados. Agora vamos remover os valores duplicados, deixando apenas os valores únicos e distintos. Selecione seus dados e, no menu “Dados”, escolha a opção “Remover Duplicatas”.
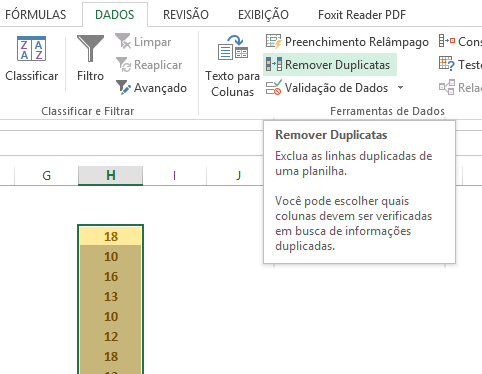

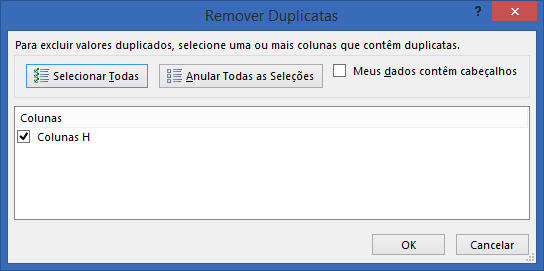
Na janela aberta, veja que a coluna H está selecionada. De “Ok” e veja o resultado.

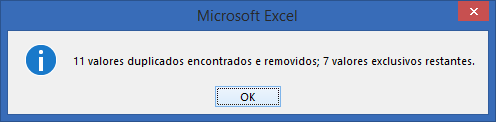
Uma janela nos avisa que 11 valores duplicados foram encontrados e removidos, restando apenas 7 valores exclusivos restantes.

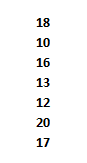

Os comandos vistos neste artigo são importantes quando precisamos, por exemplo, encontrar nomes de pessoas, produtos ou lugares (por exemplo) distintos, presentes em uma lista com grandes volumes de dados. Trabalhar com os valores distintos pode ser muito útil juntamente com a função PROCV por exemplo. Até o próximo artigo.



